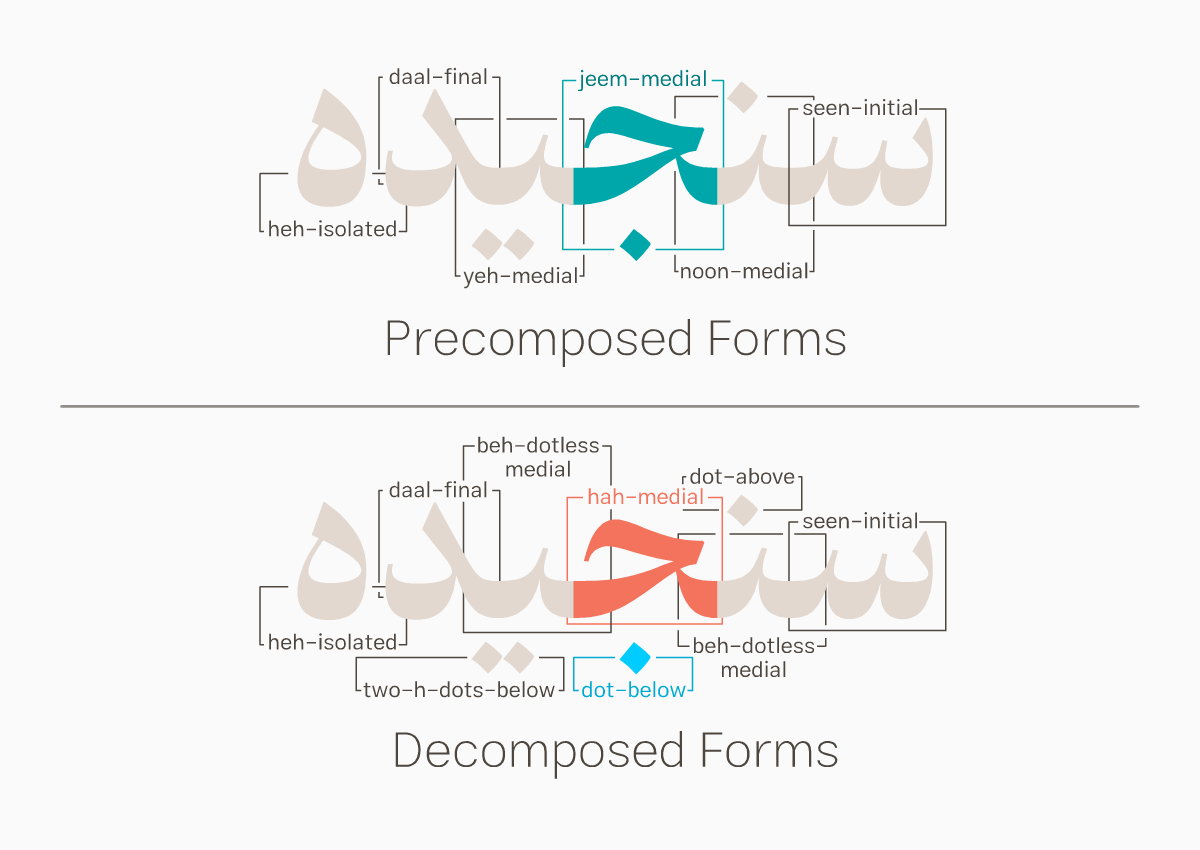
ساختارهای Precomposed و Decomposed
ساختارهای precomposed و decomposed مفاهیم مشترکی در نویسهها و روشهای ساخت فونت هستند که هر کدام مزایا و محدودیتهایی دارند. این مقاله شرح مختصری در مورد این ساختارها ارائه میدهد.
precomposed/decomposed characters
نویسۀ ö را در نظر بگیرید(نویسه=character). این نویسه به صورت کامل در آدرس U+00F6 یونیکد موجود است. این نوع از نویسهها، نویسههای پیشساخته (precomposed) هستند، زیرا با تنها یک آدرس به یک فرم ترکیب شده اشاره میکنند.
نویسۀ ö را همچنین میتوان از ترکیب o در آدرس U+006F و diaeresis comb(دو نقطۀ بالای آن) در آدرس U+0308 به دست آورد. این نوع از نویسهها، نویسههای تفکیک شده(decomposed) هستند.(البته باید خود فونت از این نویسهها و ترکیبشان با یکدیگر توسط کرنینگ یا mark پشتیبانی کند.)
گلیفهای Precomposed برای نویسههای Precomposed
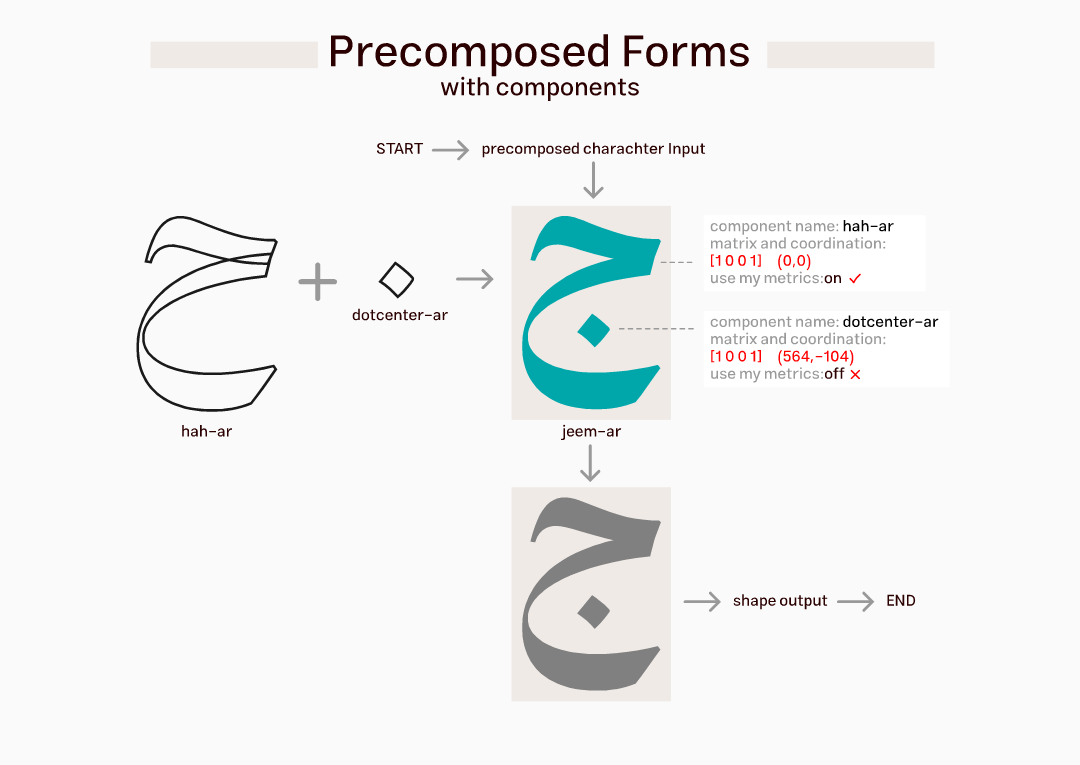
متداولترین روش ساخت گلیفهایی که نویسههای precomposed به آنها اشاره میکنند، در دورۀ فعلی (حداقل در زمان نگارش این مقاله) استفاده از اجزا(جزء = component) برای ساخت فرمهای پیشساخته است(در این مقاله به آنها precomposed forms میگوییم)، استفاده از اجزا ساخت گلیفهای ترکیب شدۀ مختلف رو تسهیل میکنند. به طور مثال حرف «ج» را میتوان از ترکیب دو جزء «ح» و «تک نقطه» ساخت. این کار هم حجم فونت را کاهش میدهد و هم به خاطر ارتباط بلادرنگ و مستقیم اجزا با فرم اصلی خودشان در نرمافزار ساخت فونت، ایجاد و ویرایش گلیفهای ترکیبی دیگر را سادهتر میکنند.
اجزا دارای چند ویژگی هستند. آنها در واقع پیوندی به فرم اصلی هستند که میتوانند ارتباطِ ریاضیِ دو بعدیِ خطیِ کامل و منعطفی با آن برقرار کنند. یک جزء دارای مختصات انتقال، ماتریس تبدیل دوبعدی برای ایجاد یک نگاشت خطی با فرم اصلی، و یک flag به اسم use_my_metrics برای تنظیم خودکار عرض گلیفی که جزء در آن استفاده شده با فرم اصلی مربوط به آن جزء است.(البته توصیۀ اغلب نرمافزارهای بررسی کنندۀ فونت، استفاده از اجزا با اندازۀ واقعی، بدون چرخش و برعکس کردن(flip) آن است(یعنی استفاده از ماتریس تبدیل واحد)).
مشکلات و محدودیتهای این ساختار
اصلیترین مشکلی که اجزا دارند نبود ارتباط با فرمهای اصلی خودشان از طریق opentype فونت است، به طور مثال نمیتوان نقطۀ «ج» را که یک جزء جداست از طریق تعویض فرم اصلی آن توسط opentype(مثلاً جایگزینی با ss01) در «ج» و تمام جاهایی که جزءِ نقطه استفاده شده است جایگزین کرد! همچنین نمیتوان نقاط را در این ساختار در موقعیتهای مختلف جابجا کرد.
یکی دیگر از مشکلات این ساختار، پیچیده شدن ساخت لیگیچرهاست. در این ساختار، تک تک لیگیچرها باید ساخته شوند که این کار در برخی موارد حجم کاری زیادی را تحمیل میکند. به طور مثال، لیگیچر «سر» را در نظر بگیرید. فرمهای مشابه حروف تشکیل دهندۀ این لیگیچر باعث میشوند این لیگیچر در اصل یکی از شش لیگیچر «سر-شر-سز-شز-سژ-شژ» باشد که باید همۀ آنها ساخته شوند، و علاوه بر این اگر حروف مشابه دیگر هم پشتیبانی شده باشند تعداد کل به صورت جایگشتی(ضرب تعداد حالات در یکدیگر) بیشتر میشود.
در حالت کلی میتوان گلیفهای precomposed یک فونت را در این ساختار بدون استفاده از اجزا، توسط کپی کردن contourها(مسیرهای بستۀ ترسیم شده) یا ایجاد contourهای جدید نیز ساخت. در اینجا به این دلیل به اجزا اشاره شد تا به نبود ارتباط بین آنها و فرمهای اصلیشان از طریق opentype پرداخته شود، زیرا در نگاه اول به نظر میرسد این ارتباط باید وجود داشته باشد، حال آنکه اینگونه نیست!
گلیفهای Decomposed برای نویسههای Precomposed
در این ساختار، همانگونه که از نام آن هم پیداست، تمام بخشهای گلیفهای مورد اشارۀ نویسههای precomposed از هم مجزا هستند و بدون دخالت اجزا و به صورت مستقیم از گلیفهای پایه ساخته میشوند. در واقع همان تفکیکی که در نویسههای decomposed وجود داشت، درون فونت توسط opentype برای تمام نویسههای precomposed صورت میگیرد(با استفاده از ccmp برای لاتین؛ البته برای عربی به دلیل وجود حالات مختلف حروف لازم است برخی از آنها توسط یکی از فیوچرهای init ، medi ، fina یا isol تفکیک شوند)(در این مقاله به آنها decomposed forms میگوییم). به طور مثال در عربی تمام نویسههای precomposed به گلیفهای بدنه، نقاط و دیگر گلیفهای تفکیک شونده(مانند سرکش گاف، یای دم کوتاه، کافچه، همزۀ کوچک، مد آ و …) تجزیه میشوند(بر خلاف decomposed characters نیازی نیست گلیفهای تجزیه شده حتماً آدرس یونیکد داشته باشند). در مراحل بعدی، این گلیفها توسط کرنینگ یا در اغلب موارد توسط markها نسبت به هم جابجا شده و شکل نهایی نویسههای پیشساخته را از گلیفهای تفکیک شدۀ فونت میسازند.
به طور مثال «ج» توسط isol به «ح» و «تک نقطۀ وسط» تجزیه شده و «تک نقطۀ وسط» توسط mark درون کاسۀ «ح» قرار میگیرد تا «ج» ساخته شود:
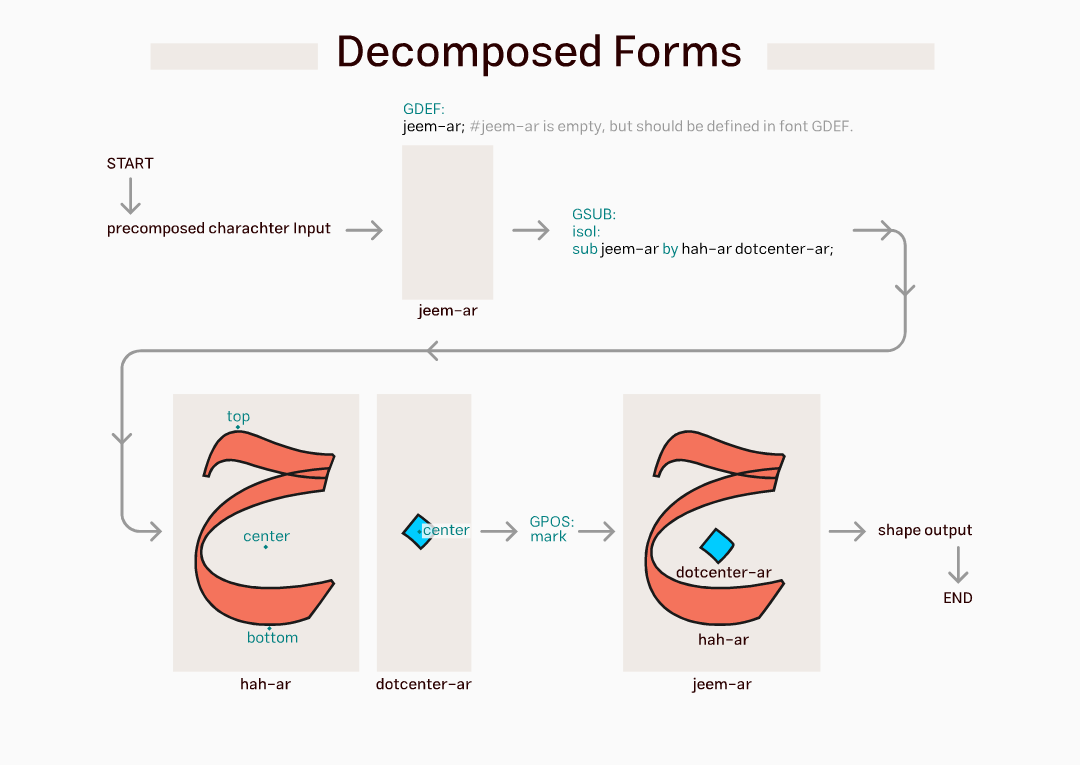
اصلیترین مزیت این ساختار در ارتباط و اتصال تمام گلیفهای پایه و دسترسی به آنها از طریق opentype است، بنابراین به طور مثال میتوان نقاط گلیفهای عربی را با فرمهای دیگر جایگزین یا در شرایط مختلف جابجا کرد. همچنین در این روش نیازی به ساخت تمام لیگیچرها نیست و فقط لازم است لیگیچرهای اصلی ساخته شوند.(البته انعطاف این ساختار در ساخت لیگیچرها از ساختار قبلی کمتر است.)
مشکلات و محدودیتهای این ساختار
مشکلاتی که این ساختار دارد معمولاً به دو گروه تقسیمبندی میشوند:
- پیچیدگی در پیادهسازی opentype در این روش، که نیازمند دانش و مهارت نسبتاً بیشتریست.
- مشکلات و ناهمگونیهایی که نرمافزارهای مختلف در پیادهسازی این روش دارند.
دید کلی
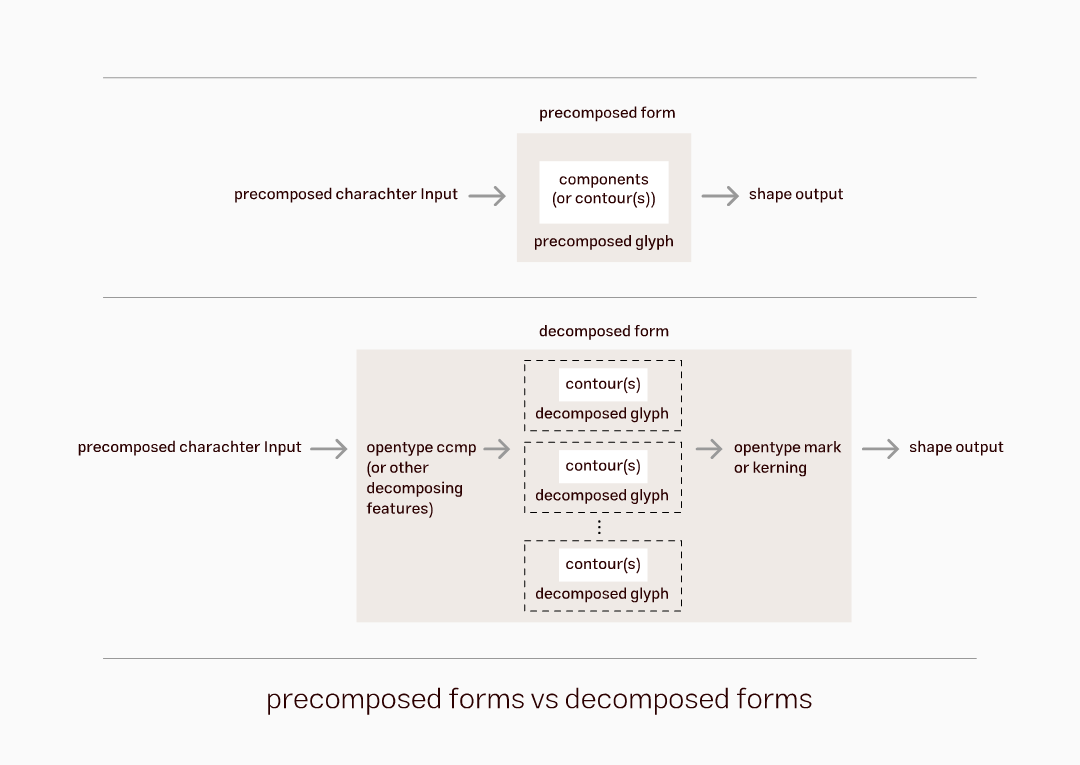
رسیدن به یک دید کلی برای انتخاب روش مناسب ساخت فونت بسیار مهم است. حتی در برخی از شرایط ممکن است لازم شود ترکیبی از هر دو روش استفاده شود، به عنوان مثال میتوان تداخل «مد آ» با خانوادۀ «ک» و نقاط «ت» و «ث» را به صورت تجزیۀ «آ» به «ا» و «مد آ» و نوشتن چند contextual positioning برای جابجایی شرطی «مد آ» برطرف کرد و در عین حال باقی فرمها را به صورت precomposed ساخت. مثالهای مشابه بیشتری از این دست وجود دارند… به صورت اجمالی میتوان decomposed forms و precomposed forms را به صورت زیر نشان داد:
آیا میتوان از هر دو روش برای ساخت گلیفهای Precomposed یک فونت استفاده کرد؟
بله. میتوان در یک فونت از هر دو روش استفاده کرد اما استاندارد Unicode NFC normalization در هنگام تایپ متن تمام نویسههای decomposed را در صورت پشتیبانی، تبدیل به نویسههای precomposed میکند، علت این کار تطابق دنبالههای مختلف از نویسههای متفاوت با یکدیگر و کاهش حجم ذخیرۀ اطلاعات است. بنابراین استفادۀ همزمان از هر دو روش غیرضروری و حتی در برخی موارد بیهوده به نظر میرسد.
گسترش مفاهیم decomposed و precomposed در نویسهها
میتوان مفاهیم precomposed و decomposed را در مورد نویسههای دیگر نیز بسط داد. به عنوان مثال حرکهگذاری در عربی کاملاً به صورت decomposed انجام میشود، اما برای نویسههای پرکاربرد precomposed مانند «أ» که از دو جزء تشکلی شدهاند در ابتدا ثبت شده و امروزه هم استفاده میشود. با همین پیشفرض ذهنی میشد انتظار داشت که برای نویسههای دیگر عربی با اعرابگذاریهای دیگر هم نویسههای precomposed دیگری وجود داشته باشند. اما چه چیزی باعث شده است این روال متوقف شود؟ مثلاً چرا برای «بُ» یک نویسۀ جداگانۀ precomposed نداریم؟ علت اصلی این مسئله احتمالاً مربوط به بالا رفتن غیرضروری تنوع نویسهها و نیاز به ثبت کیبوردهایی با تعداد ورودیهای بسیار زیاد برای وارد کردن آنهاست. این روند بیهوده و آزاردهنده در لاتین تقریباً تکمیل شده و چون Unicode دارای backward compatibility است(یعنی بروزرسانیهای جدید باید با نسخههای قبلی هماهنگ باشد)، نمیتوان نویسههای ثبت شده را حذف کرد. بنابراین میتوان نتیجه گرفت حد تعادلی برای استفاده از هر دو ساختار در ثبت نویسهها وجود دارد که باید رعایت شود.
مثالها
فونتهای سیستمی معمولاً از precomposed forms استفاده میکنند اما از هر دو نوع ورودی نویسه(precomposed/decomposed characters) نیز پشتیبانی میکنند(احتمالاً برای سازگاری حداکثری). سیستمهای بسته مانند فونتهای مریم سافت از decomposed forms استفاده میکنند چون مزایای بیشتری دارد(مخصوصاً برای جابجایی نقاط). غیر از دو گروه بالا، اغلب فونتهای موجود در مارکت ایران و جهان به روش precomposed forms ساخته میشوند(مانند تمام فونتهای فونتامین تا تاریخ انتشار این مقاله) و فونتهای کمی وجود دارند که به روش decomposed forms ساخته شدهاند. یکی از این فونتها که به تازگی منتشر شده فونت سپید است.


نظرات