
متون دوسویه و نحوۀ مواجهه با آنها در محیط دیجیتال
فرض کنید حروفچین یک روزنامۀ قدیمی هستید که در آن تمام حروف و علائم را کلیشههای سربی تشکیل دادهاند، اگر فرض کنیم روزنامه فارسی باشد ترتیب چینش کلیشهها از راست به چپ و در راستای خواندن حروف فارسی اتفاق میوفتد، اما اگر بین جملات فارسی چند کلمۀ انگلیسی داشته باشیم چطور؟ جهت خواندن حروف انگلیسی چپ به راست است بنابراین با ترتیب چینش راست به چپ، حروف انگلیسی باید به صورت معکوس و از آخر به اول حروفچینی شوند. به صورت مشابه در یک روزنامۀ انگلیسی با چینش حروف از چپ به راست، حروف فارسی باید به صورت معکوس چیده شوند. بنابراین «جهت چینش نویسهها» و «جهت خواندن» همواره برابر نیست و چینش نویسهها مخصوصاً در متنونی که خطوط نوشتارهای از هر دو جهت دارند میتواند چالشآفرین باشد(نویسه = character). موضوع این مقاله در مورد نحوۀ مواجهه با همین چالشها در محیطهای نرمافزاریست.
متن دوسویه
همانگونه که میدانیم در خطوط نوشتاری مختلفْ فرآیند نوشتن در یک جهت مشخص و همیشگی اتفاق میافتد، این جهت یکی از ویژگیهای ذاتی و غیرقابل تغییرِ هر کدام از خطوط نوشتاریست. برای مثال خط عربی و عبری در جهت راست به چپ، و لاتین و سیرلیک در جهت چپ به راست نوشته میشوند. در هر کدام از این خطوط نوشتاریْ حرف قبلی و بعدی نسبت به جهت خط نوشتاری تعیین میشوند. این جهات مختلف سبب بوجود آمدن شرایط پیچیده در متونی میشود که به صورت «همزمان» دارای بلوکهای متنی از خطوط نوشتاری هر دو گروه با جهات مختلف هستند. به متنی که نویسههایی از هر دو گروه خطوط نوشتاری با جهت راست به چپ، و چپ به راست دارد، متن دوسویه یا Bidirectional Text گفته میشود.
واژهشناسی
در ابتدا بهتر است با چند واژه و مفهومِ مختص و کاربردی این مبحث آشنا شویم:
جهت متن(text direction): جهت کلی غالب بر چینش بلوکهای متنی(کلمات و عبارات یکپارچۀ متشکل از یک خط نوشتاری) در یک سند را جهت متن میگوییم(فارسی یا انگلیسی بودن روزنامه در مثال بالا).
نویسۀ قوی: نویسههای اختصاصیِ اغلب خطوط نوشتاری، نویسههای قوی هستند(مانند نویسۀ «ب» برای عربی). نویسههای قوی از جهتِ ذاتی و غیرقابل تغییرِ خط نوشتاری که به آن تعلق دارند پیروی میکنند.
نویسۀ ضعیف: علائم حسابی، ارقام عربی-اروپایی و … جزو نویسههای ضعیف هستند. جهت چینش برخی از نویسههای ضعیف(مانند علائم حسابی) تابع جهت چینش نویسههای قوی همسایۀ خود است و اگر در یک طرف همسایگی خود نویسۀ قوی چپ به راست و در طرف دیگر نویسۀ قوی راست به چپ باشد، این طیف از نویسههای ضعیف، جهت متن را خواهند پذیرفت. برخی دیگر از نویسههای ضعیف(مانند ارقام عربی-اروپایی) جهت ذاتی و ثابتی برای چینش دارند اما جهت نویسههای همسایۀ خود را جز در موارد استثنایی تغییر نمیدهند و از این رو جزو نویسههای ضعیف طبقهبندی شدهاند.
نویسۀ خنثی: نویسههایی که ذاتاً دارای جهت نیستند مانند tab، جداکنندۀ پاراگراف و دیگر نویسههای فاصله. برای تعیین جهت چینش نویسههای خنثی نیز همانند نویسههای ضعیفِ بدون جهت عمل میشود.
قالببندی صریح: روشهایی که در آنها توسط نویسههای کنترلی یونیکد(نویسههای غیرچاپی) به کاربر اجازه داده میشود در کار پیشفرض نرمافزار برای چینش نویسهها دخالت کند. این کار برای رفع خطاهای غیرعمدی بوجودآمده توسط نرمافزار یا انجام موارد خاص، به صورت دستی انجام میشود.
ذخیرهسازی دادهها در سیستمهای رایانهای
برای اینکه پیچیدگیهای جهات مختلف خطوط نوشتاری وارد سیستم ذخیرهسازی اطلاعات نشود، وظیفۀ تشخیص و اعمال جهت خط نوشتار بر عهدۀ بخش مشخصی از نرمافزارهای واژهپرداز است، بنابراین «در سیستمهای رایانهای، نویسهها در آدرسهای حافظه با همان ترتیبی که در متن خوانده میشوند ذخیره میگردند» (لبته ممکن است موارد استثنا، به خصوص در سیستمهای قدیمی وجود داشته باشد). چالشِ «تطبیق چینش نویسههای متن با جهت خطوط نوشتاری» همواره بر عهدۀ واژهپرداز است.
تجزیه و تحلیل متون دوسویه (Bidirectional analyses)
برای تجزیه و تحلیل و چینش نویسههای یک متن دوسویهْ باید جهت تمام نویسهها از قبل مشخص باشد، این تعیین جهت نه تنها روی چینش، که روی شکل نهایی آنها متأثر از تبدیلات و جابجاییهای opentype تأثیرگذار است، این مسئله در مورد یک خط نوشتاری مانند عربی که حالات مختلف حروف در ابتدا، میان، انتها و به صورت جدا، با هم تفاوت دارند باعث تبعات دامنهدارتری میشود.
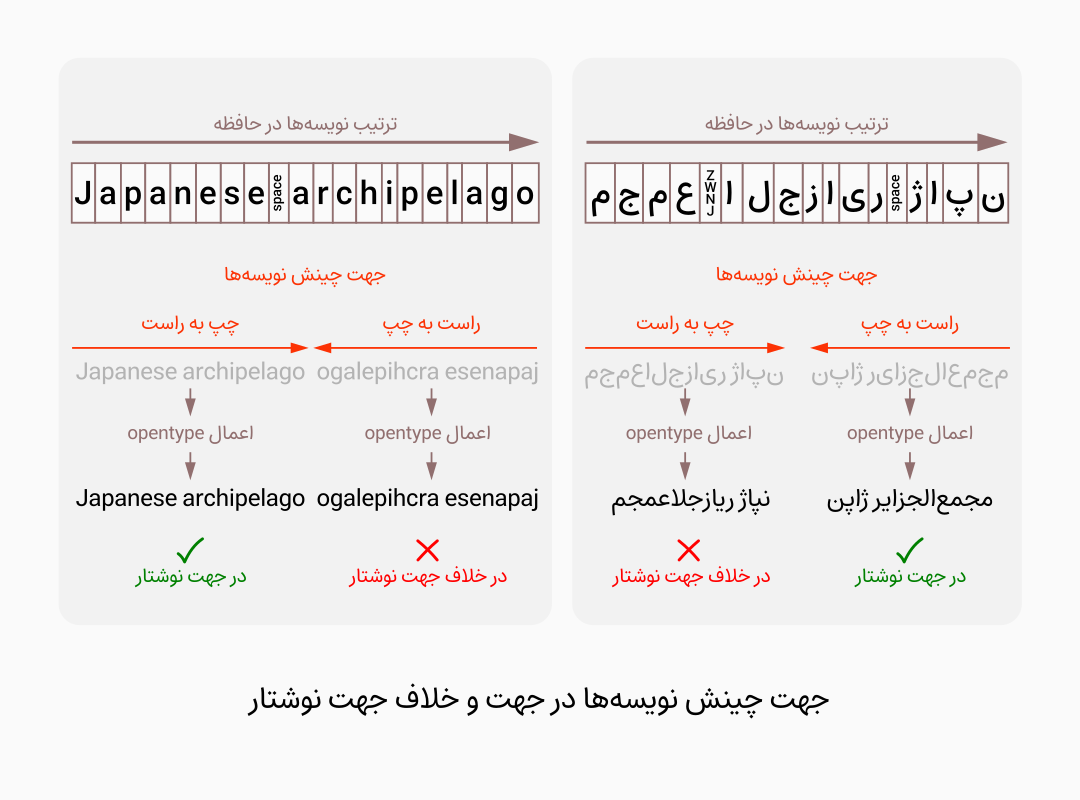
تفاوت تحلیل متون دوسویه(Bidirectional Analyses)، جهت متن(Text Direction) و ترازبندی (justification)
در متون دوسویه بحث بر سر «جهت درست چینش نویسهها با جهات چینش متفاوت» است.
جهت متن، در مورد «جهت چینش بلوکهای متن تشکیل شده از خطوط نوشتاری مختلف»(اینکه به طور مثال یک روزنامه فارسی دارای چند جملۀ انگلیسیست یا یک روزنامۀ انگلیسی دارای چند جملۀ فارسیست، تفاوت در ترتیب چینش این بلوکها بر اساس انتظار کاربر از جهت کلی متن اتفاق میوفتد، اینکه چشم کاربر از سمت راست در طول سطر حرکت میکند یا از سمت چپ).
ترازبندی متون، در مورد «تراز کردن سطرهای یک یا چند پاراگرافها در سمت راست یا چپ» است.
برای انجام ترازبندی درست و تعیین جهت متن میتوان از جهت خط نوشتاری اصلی در محتوای متنی کمک گرفت.
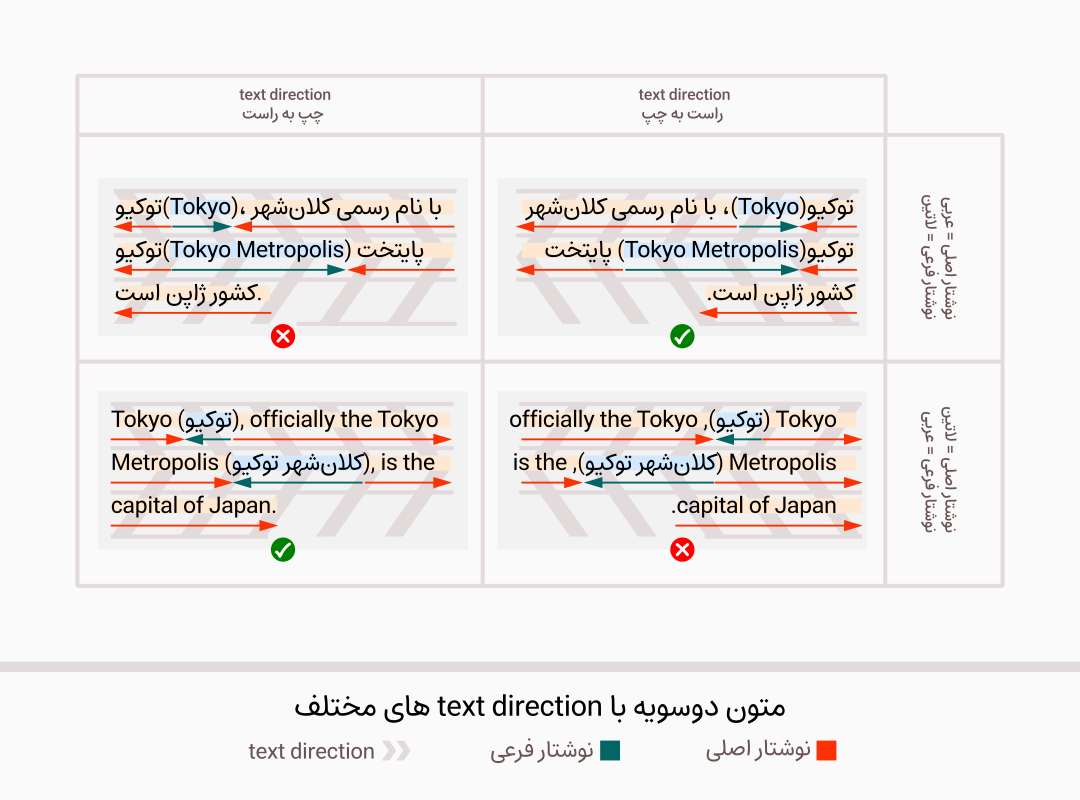
قالببندی صریح و تغییر جهت چینش نویسههای ضعیف
گاهی لازم است جهت برخی از نویسههای ضعیف و خنثی و حتی در موارد نادر جهت چینش خود نویسههای قوی عوض شده و در جهت عکس چیده شوند، در این موارد میتوان از نویسههای قالببندی که برای همین کار ثبت شدهاند استفاده کرد. نویسههای قالببندی انواع مختلفی دارند:
Marks
نویسههای شبهقوی کنترلی یونیکد که میتوان آنها را برای تغییر جهت چینش نویسههای ضعیف، در همسایگی آنها وارد کرد.
LRM(Left to right Mark)، RLM(Right to Left Mark) و ALM(Arabic letter Mark) سه نویسۀ Mark برای این روش هستند.(ALM شبیه به RLM عمل میکند اما محدودۀ تاثیر آن با RLM متفاوت است)
Embeddings
روش کلاسیک یونیکد که چینش مقداری از متن تعیین شده در یک محدوده را توسط نویسههای کنترلی، متمایز میکند. این روش، متن متمایز شده را از نظر بصری از بقیۀ متن جدا نمیکند اما بر آنها تأثیر میگذارد. این روش از یونیکد نسخۀ 6.3 به خاطر تأثیر قوی بر محیط اطراف و به نفع Isolates کنار گذاشته شده است.
Isolates
روش Isolate بسیار شبیه به embedding است با این حال، در حالی که یک embedding تقریباً تأثیر یک نویسۀ قوی بر ترتیب متن اطراف را دارد، یک Isolate تأثیر یک نویسۀ خنثی مانند U+FFFC OBJECT REPLACEMENT CHARACTER را دارد و موقعیت نمایش مربوطه را در متن اطراف به آن اختصاص میدهد. علاوه بر این، متن داخل Isolate تأثیری در ترتیب متن در خارج از آن ندارد اما embedding تأثیرگذار است.
Overrides
در موارد خاص برای لغو کلی جهت چینش تمام نویسهها در یک جهت(حتی نویسههای قوی) از کاراکترهای کنترلی RLO(Right to Left Override) و LRO(Left to right Override) استفاده میشود. توصیه شده حدالامکان از این نویسههای کنترلی استفاده نشود.(موارد کاربرد آن بسیار کم و تخصصیست)
Pops
pop ها نویسههای کنترلی برای خاتمه دادن به محدودههای embedding، override و isolate هستند.
دو pop اصلی در دو متد Embeddings و Isolates عبارت است از PDF(POP DIRECTIONAL FORMATTING) و PDI(POP DIRECTIONAL ISOLATE) هستند.
Runs
در الگوریتم تحلیل متون دوسویه، به هر دنباله از نویسههای قویِ به هم پیوسته، یک run گفته می شود.
چند مثال کاربردی از قالببندی صریح
مثال اول:
زبان برنامه نویسی C++ یک زبان سطح پایین است.
در مثال بالا ++ بعد از C نوشته شده و در مجموع و با ترتیب چپ به راست(و نه ترتیب نوشته شده در بالا) معرف یک زبان برنامهنویسی است. در یک متن فارسی(با خط نوشتار عربی راست به چپ) ++ بعد از C در سمت چپ آن قرار خواهد گرفت زیرا ++ به انضمام نویسۀ فاصلۀ بعد از آن، یک عبارت با 2 نویسۀ ضعیف بدون جهت و یک نویسۀ خنثی است که بعد از نویسۀ قوی چپ به راست «C» و قبل از نویسۀ قوی راست به چپ «ی»(واقع شده در ابتدای کلمۀ «یک») قرار گرفته است. در چنین شرایطی ++ و فاصلۀ بعد از آن از جهت متن نوشتار اصلی تبعیت خواهند کرد که در اینجا راست به چپ است. برای اصلاح این عبارت چندین راه وجود دارد، سادهترین راه اضافه کردن یک LRM بعد از ++ است. در این صورت ++ در همسایگی دو نویسۀ قوی چپ به راست بوده و از جهت چینش آنها تبعیت خواهد کرد. نتیجۀ این اصلاح:
زبان برنامه نویسیC++ یک زبان سطح پایین است.
موضوع بسیار ساده است، اگر بعد از ++ حروف D قرار میگرفت، عبارت به صورت C++D در میآمد که در آن، موقعیت C و ++ همان وضعیت درست و دلخواه ماست، بنابراین به جای D یک نویسۀ قوی نامرئی نیاز داریم که همان LRM است.
مثال دوم:
برندگان رقابت به ترتیب kevin ، michel و james هستند.
در این مثال چون «،» یک نویسۀ ضعیف محسوب میشود، بنابراین عبارت «kevin ، michel» مانند یک run چپ به راست یکپارچه عمل میکند و kevin که اول است با جهت خوانش راست به چپ تبدیل به برندۀ دوم رقابت میشود! برای اینکه این ترتیب اصلاح شود کافیست بعد از «،» یک RLM یا ALM اضافه کنیم. نتیجۀ این اصلاح(با افزودن RLM):
برندگان رقابت به ترتیب kevin ، michel و james هستند.
مثال سوم:
اسم کتاب You’re Only Old Once! است.
در مثال بالا علامت تعجب چون در همسایگی دو نویسۀ قوی از دو جهت مختلف واقع شده، از جهت نوشتار اصلی که راست به چپ است تبعیت میکند. وضعیت شبیه به مثال اول است، بنابراین در اینجا هم میتوانیم با افزودن نویسۀ LRM بعد از علامت تعجب، ترتیب چینش آن را اصلاح کنیم:
اسم کتاب You’re Only Old Once! است.
در همین مثال میتوانستیم از روشهای دیگر نیز استفاده کنیم. به طور مثال با استفاده از روش isolates میتوانستیم نویسۀ LRI را قبل از Y و PDI را بعد از علامت تعجب وارد کنیم تا تمام نویسههای لاتین نام کتاب و علامت تعجب به صورت چپ به راست چیده شوند.
نویسههای آیینهای
در ابتدای مقاله اشاره کردیم که نویسۀ قبلی و بعدی در هر خط نوشتاری نسبت به جهت آن تعیین میشود. بنابراین نویسۀ قبلی و بعدی در یک خط نوشتاری راست به چپ مانند عربی به ترتیب در سمت راست و چپ، و در یک خط نوشتاری چپ به راست مانند لاتین به ترتیب در سمت چپ و راست واقع میشوند. الگوریتم دوسویه برای نویسههای آیینهای مانند [] () {} «» <> و … که برای دربرگرفتن بخشی از یک متن یا مقایسۀ اعداد و عبارات به کار میروند به کاربرد آنها در متون چپ به راست یا راست به چپ اصلاحات متناسبی انجام میدهد. تصویر زیر یک مثال در همین مورد را نشان میدهد:

تصحیح یک برداشت اشتباه
آیا نمیشود از همان ابتدا با تغییر توالی نویسهها در وارد کردن اطلاعات، ظاهر متن را اصلاح کرد؟
این کار ممکن است از نظر عملی در موارد زیادی انجامپذیر باشد اما به صحت و اعتبار اطلاعات ذخیرهسازی شده صدمۀ جدی وارد میکند و ممکن است در محیطهای نمایشی با تفاسیر متفاوت منجر به نمایش نادرست اطلاعات شود.
قاعدۀ First-strong برای تعیین Text-Direction
جهت متنْ در یک محیطِ ویرایشِ متنِ قوی مانند Microsoft office میتواند توسط کاربر یا سیستم انتخاب شود اما در محیطهای نرمافزاری که ابزار ویرایش متن سادهتری برای کاربران عادی دارند از قواعد خودکار مختلفی استفاده میشود، مانند جهت متن ثابت یا تعیین جهت متن خودکار با بررسیِ برتریِ نسبیِ تعداد نویسههای قوی از خطوط نوشتاری مختلف.
یکی از رایجترین روشهای تعیین جهت متن خودکار، نمونهبرداری از اولین نویسۀ قوی(روش First-Strong) است. در این روش تا وارد شدن اولین نویسۀ قوی، جهت متن پیشفرضی وجود دارد(معمولاً جهت همسو با تنظیمات زبان سیستم) که نویسههای خنثی و ضعیف از آن تبعیت میکنند، با ورود اولین نویسۀ قوی، جهت متن در راستای جهت آن نویسه تنظیم میشود. این روش معمولاً خروجی قابل اعتمادی دارد به شرطی که کاربران یک سیستم از خط نوشتاری برعکس خود برای اولین ورودی استفاده نکنند.(برای کاربران فارسی اگر اولین کلمه لاتین و محتوای کلی متن فارسی باشد جهت متن خراب خواهد شد)
منابع:
چند سوال از جناب روزبه پورنادر در توئیتر که به روشن شدن مطلب کمک کرد. با تشکر از ایشان.


متن تخصصی و قشنگی بود. ممنون از شما.
ممنون از توجه و محبت شما.
بسیار عالی.
ممنونم 🙂