مقدمهای بر کدگذاری نویسهها و ساختار اطلاعات دیجیتال
این مقاله در مورد کدگذاری نویسهها(character encoding) و شرح و تفصیل مختصری از مفاهیم مربوط به آنهاست. آشناییِ ابتدایی با ساختار اطلاعات در سیستمهای دیجیتال کمک میکند با بخشی از فرآیندِ نرمافزاریِ ایجاد، ویرایش، انتقال، ذخیره، رمزگشایی و نمایش متون در رایانهها و همچنین ساز و کار یونیکد و اُپنتایپ در همین محدوده آشنا شویم.
کدگذاری چیست؟
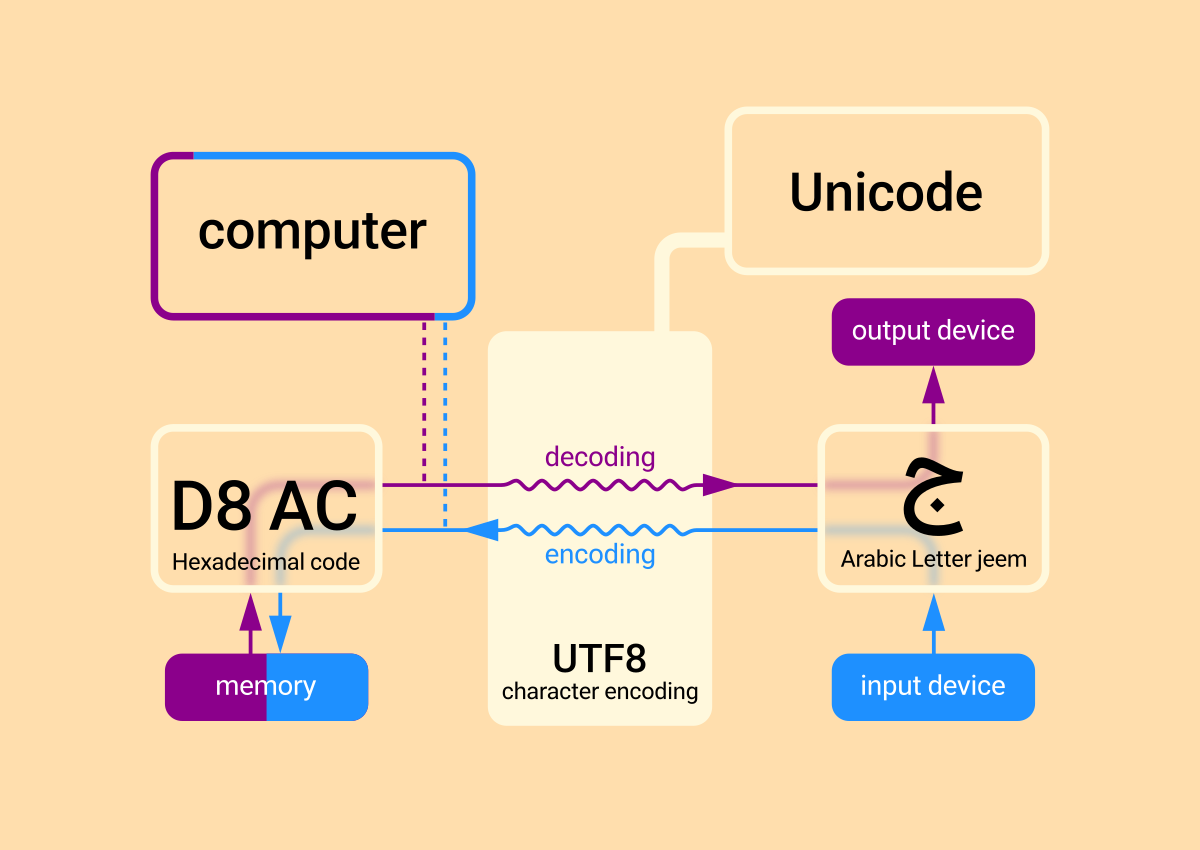
کدگذاری به مرتبط کردن حروف و علائم دستهبندی شدۀ دلخواهْ با اعداد حسابیِ ترتیبی(0، 1، 2 و …) برای ارتباط با سیستمهای رایانهای گفته میشود. در حقیقت رایانهها به دلیل ساختارشان فقط اعداد را میفهمند در حالیکه انسانها علاوه بر اعدادْ از حروف و علائم نیز استفاده میکنند، بنابراین لازم است برای ارتباط دو طرفه با رایانهها، حروف و علائمی که میخواهیم در یک دستهبندی مشخص و از پیش تعیین شده از آنها استفاده شود، توسط یک قرارداد(یکی از استانداردهای کدگذاری مثل ASCII) با اعدادی که به ترتیب از صفر شروع میشوند مرتبط و به رایانه معرفی شود. در واقع کدگذاریها در حکم فرهنگ لغتْ برای ارتباط دوطرفۀ انسانها و رایانهها با یکدیگر است!
برای مثال در کدگذاری ASCII برای اشاره به حرف A باید عدد 65 به رایانه ارسال شود، این کار توسط کیبوردهای واقعی(در رایانهها، لپتاپها، گوشیهای دکمهای و …) یا کیبوردهای مجازی(در صفحات نمایشی لمسی در رایانهها، گوشیهای هوشمند، تبلتها و …) و وسایل الکترونیکیِ مشابه انجام میشود، بدون آنکه نیاز باشد عدد مربوط به هر حرف و علامت را بدانیم. در واقع کیبوردها یک رابط مستقیم برای تبدیل علائم، حروف و اعداد از خطوط نوشتاری مختلف به اعداد قابل فهم برای رایانهْ تحت یک کدگذاریِ از پیش تعیین شده توسط کاربر یا انتخاب شده به صورت پیشفرضْ توسط خود رایانه هستند.(در اینجا رایانهْ بوسیلۀ یک ابزار ورودی که توسط انسان استفاده شده و برای او قابل فهم است و تحت یک کدگذاریْ زبانِ انسان را برای رایانه ترجمه میکند)
برای انتقال و نمایش یک فایل متن دیجیتال از حافظۀ رایانه یا رایانههای دیگر به صفحه نمایش(یا برای چاپ) نیز اتفاق مشابهی در جهت عکس رخ میدهد، یعنی مجموعهای از اعداد قابل فهم برای رایانه که در یک حافظه ذخیره شدهاند توسط یکی از استانداردهای کدگذاری(که از قبل در اطلاعات خود فایل مشخص شده است یا سیستم خود تشخیص داده) توسط یک واژهپرداز رمزگشایی شده و به یکی از زبانهای قابل فهم برای انسانها در خروجی نمایش داده میشود.(در اینجا رایانه بوسیلۀ کدگذاریْ زبانِ رایانه را برای انسان ترجمه و دنبالهای از نویسههای ترسیم شده تحت یک فونت انتخاب شده یا پیشفرض را به یکی از دستگاههای خروجی مانند چاپگر یا صفحهنمایش ارسال میکند)
(واژهپرداز بخشهای مختلفی مانند خواندن دادهها، تبدیل محتوای اصلی فایل دیجیتال به حروف و علائم متناظر خود در کدگذاری(نوع کدگذاری معمولاً در اطلاعات ابتدایی فایل مشخص میشود)، ترسیم تکتک حروف و علائم در اندازههای تعیین شده یا پیشفرض با فونت انتخاب شده یا پیشفرض(با ویژگیهای اپنتایپِ انتخاب شده یا پیشفرض) و اِعمال استایل(رنگ، شفافیت و …)، تحلیل متون دوسویه، چیدن تصاویر به دست آمده از رندر حروف و علائم به دست آمده یا استخراج شده(که اندازۀ آنها قبلاً در تنظیمات فونت یا به صورت پیشفرض مشخص شدهِ) در طول سطر، شکستن سطرها در کادر متن و … را شامل میشود)
با آنکه هر چه محدودۀ اعداد مورد استفاده کمتر باشد، تعداد حروف و علائم دستهبندی شده نیز کمتر است، در عوض سرعت انتقال این اعداد بیشتر و حجمی که در این انتقال و ذخیرۀ آنها مصرف میشود کمتر خواهد بود، در نتیجه تعداد کمتر یا بیشتر حروف و علائم دستهبندی شده، هم از جانبی مزیت تلقی شده و هم از طرفی محدودیت بوجود میآورد.
| تعداد نویسههای کدگذاری | برتری | ضعف |
|---|---|---|
| کم | حجم دادهها در انتقال و ذخیره کمتر است | حروف و علائم کمتری را میتوان پوشش داد |
| زیاد | حروف و علائم بیشتری را میتوان پوشش داد | حجم دادهها در انتقال و ذخیره بیشتر است |
اعداد دودویی و هگزادسیمال
عدد مربوط به یک حرف یا علامت در کدگذاریهای مختلف متفاوت است و چون رایانهها فقط صفر و یک را میفهمند، برای بیان آنها از اعداد دودویی(اعداد در مبنای 2) یا هگزادسیمال(اعداد در مبنای 16) استفاده میشود.
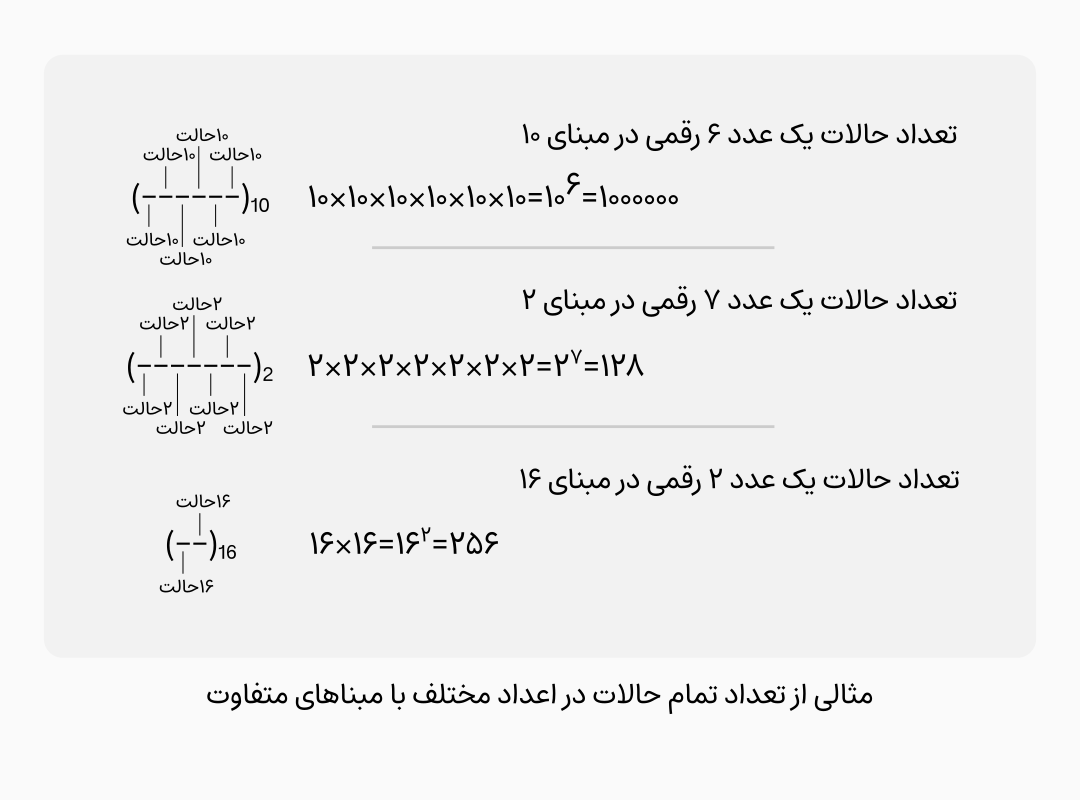
ما برای خواندن و نوشتن اعداد معمولی از یک قرارداد مشخص استفاده میکنیم. در این قرار داد از 10 علامت برای نشان دادن اعداد 0 تا 9 و برای اعداد بالاتر از 9، از نوشتن همین علامتها کنار هم و ارزشدهی متفاوت به آنها استفاده میکنیم. برای مثال عدد منحصر به فردی برای نمایش عدد «بیست و پنج» وجود ندارد اما قرار داد کردهایم که از یک عدد 2 به معنی دو بستۀ 10 تایی و یک عدد 5 در سمت راست آن استفاده کنیم و حاصل این ترکیب را «بیست و پنج» بخوانیم.
10 عدد بودن اعداد 0 تا 9 و بستۀ 10 تایی با یکدیگر ارتباط دارند. در واقع تعداد اعداد برای بستهبندی، مبنای آن سیستم عددی را مشخص میکند. در اعداد دودویی اعداد در بستههایی با تفکیک به تعداد توانهایی از عدد 2 و در اعداد هگزادسیمال به همین ترتیب در بستهبندیهایی به توانهای 16 است.

در سیستمهای رایانهای همه چیز از ترانزیستورهایی ساخته شدهاند که فقط دو حالت پایدار دارند، بنابراین تنها اعداد صفر و یک معنی پیدا میکنند و به ناچار باید از اعداد دودویی استفاده کرد.
چون اعداد دودویی طول بیشتر و قابلیت فهم و انتقال کمتری دارند و سخت میتوان آنها را به خاطر سپرد، برای بیان کدگذاریها از اعداد هگزادسیمال استفاده میکنیم. این اعداد در مبنای 16 نوشته میشوند بنابراین برای اعداد 10 تا 15 در این مبنا نیز باید علائمی داشته باشیم، برای بیان آنها به ترتیب از حروف A تا E استفاده میشود. اعداد هگزادسیمال با بستهبندی چهارتایی اعداد دودویی نیز به دست میآیند(و بالعکس تبدیل میشوند).
در علوم رایانهای به کوچکترین عدد دودویی (که وضعیت یک ترانزیستور یا فلیپ فلاپ را مشخص میکند) یک بیت و به عدد 8 رقمی دودویی (که معادل یک عدد 2 رقمی هگزادسیمال است) یک بایت گفته میشود. معمولاً سرعت انتقال به کیلو بیت بر ثانیه(و کیلو/مگا/گیگا/ترا بیت/بایت در ثانیه) و حجم حافظهها به کیلو/مگا/گیگا/ترا بایت مشخص میشود.

تعداد حروف و علائمی که در یک کدگذاری استفاده میشوند همواره با تعداد تمام حالاتی که یک عدد با تعداد ارقام ثابت دودویی میتواند داشته باشد مشخص میشود. به این عدد که به لحاظ ریاضی همواره توانی از عدد 2(به عبارت دقیقتر برابر با 2 به توان تعداد ارقام) خواهد بود «عرض بیت» آن کدگذاری گفته میشود. برای مثال کدگذاری ASCII دارای 7 بیت است، بنابراین تعداد تمام حالات آن میشود 2 به توان ۷ که برابر است با 128 حالت.
انواع کدگذاری
کدگذاری ASCII:
در ابتدای توسعۀ سیستمهای دیجیتالْ اولین کدگذاریها از ماشینهای تایپ الهام گرفته شده و تعداد حروف و علائم محدودی را پشتیبانی میکردند. یکی از اولین کدگذاریها ASCII (مخفف American Standard Code for Information Interchange) بود که اکنون بعد از بروزرسانیهای نهایی جمعاً 128 نویسه شامل حروف لاتین پرکاربرد، علائم سجاوندی و نویسههای کنترلیِ ضروری را شامل میشود.(نویسههای کنترلی شامل کاراکترهایی هستند که برای سازماندهی متن به کار میروند، مانند پاک کردن یک کاراکتر، رفتن به سطر جدید و … در حقیقت بخش بزرگی از 32 آدرس اول به دلیل تکاملِ تدریجیِ سیستمهای قدیمی، منسوخ شدهاند)
Dec Binary Hex Char Dec Binary Hex Char Dec Binary Hex Char Dec Binary Hex Char
----------------------- ---------------------- ---------------------- -----------------------
0 00000000 00 NUL (null) 32 00100000 20 SPACE 64 01000000 40 @ 96 01100000 60 `
1 00000001 01 SOH (start of heading) 33 00100001 21 ! 65 01000001 41 A 97 01100001 61 a
2 00000010 02 STX (start of text) 34 00100010 22 " 66 01000010 42 B 98 01100010 62 b
3 00000011 03 ETX (end of text) 35 00100011 23 # 67 01000011 43 C 99 01100011 63 c
4 00000100 04 EOT (end of transmission) 36 00100100 24 $ 68 01000100 44 D 100 01100100 64 d
5 00000101 05 ENQ (enquiry) 37 00100101 25 % 69 01000101 45 E 101 01100101 65 e
6 00000110 06 ACK (acknowledge) 38 00100110 26 & 70 01000110 46 F 102 01100110 66 f
7 00000111 07 BEL (bell) 39 00100111 27 ' 71 01000111 47 G 103 01100111 67 g
8 00001000 08 BS (backspace) 40 00101000 28 ( 72 01001000 48 H 104 01101000 68 h
9 00001001 09 TAB (horizontal tab) 41 00101001 29 ) 73 01001001 49 I 105 01101001 69 i
10 00001010 0A LF (NL line feed, new line) 42 00101010 2A * 74 01001010 4A J 106 01101010 6A j
11 00001011 0B VT (vertical tab) 43 00101011 2B + 75 01001011 4B K 107 01101011 6B k
12 00001100 0C FF (NP form feed, new page) 44 00101100 2C , 76 01001100 4C L 108 01101100 6C l
13 00001101 0D CR (carriage return) 45 00101101 2D - 77 01001101 4D M 109 01101101 6D m
14 00001110 0E SO (shift out) 46 00101110 2E . 78 01001110 4E N 110 01101110 6E n
15 00001111 0F SI (shift in) 47 00101111 2F / 79 01001111 4F O 111 01101111 6F o
16 00010000 10 DLE (data link escape) 48 00110000 30 0 80 01010000 50 P 112 01110000 70 p
17 00010001 11 DC1 (device control 1) 49 00110001 31 1 81 01010001 51 Q 113 01110001 71 q
18 00010010 12 DC2 (device control 2) 50 00110010 32 2 82 01010010 52 R 114 01110010 72 r
19 00010011 13 DC3 (device control 3) 51 00110011 33 3 83 01010011 53 S 115 01110011 73 s
20 00010100 14 DC4 (device control 4) 52 00110100 34 4 84 01010100 54 T 116 01110100 74 t
21 00010101 15 NAK (negative acknowledge) 53 00110101 35 5 85 01010101 55 U 117 01110101 75 u
22 00010110 16 SYN (synchronous idle) 54 00110110 36 6 86 01010110 56 V 118 01110110 76 v
23 00010111 17 ETB (end of trans. block) 55 00110111 37 7 87 01010111 57 W 119 01110111 77 w
24 00011000 18 CAN (cancel) 56 00111000 38 8 88 01011000 58 X 120 01111000 78 x
25 00011001 19 EM (end of medium) 57 00111001 39 9 89 01011001 59 Y 121 01111001 79 y
26 00011010 1A SUB (substitute) 58 00111010 3A : 90 01011010 5A Z 122 01111010 7A z
27 00011011 1B ESC (escape) 59 00111011 3B ; 91 01011011 5B [ 123 01111011 7B {
28 00011100 1C FS (file separator) 60 00111100 3C < 92 01011100 5C \ 124 01111100 7C |
29 00011101 1D GS (group separator) 61 00111101 3D = 93 01011101 5D ] 125 01111101 7D }
30 00011110 1E RS (record separator) 62 00111110 3E > 94 01011110 5E ^ 126 01111110 7E ~
31 00011111 1F US (unit separator) 63 00111111 3F ? 95 01011111 5F _ 127 01111111 7F DEL
کدگذاریهای محلی
به مرور زمان و توسعۀ علوم دیجیتال، کدگذاریهای یک بایتی در رایانهها رایج شد که یک بیت بیشتر از کدگذاری 7 بیتی ASCII داشت، بنابراین غیر از 128 آدس اولیه که توسط نویسههای ASCII اشغال شده بود 128 آدرس خالی دیگر داشت که در ابتدای امر با توجه به نیاز و به دلخواه شرکتهای سازندۀ رایانه پر میشد. شرکتی که در نقطهای از جهان این 128 را با توجه به نویسههای موردنیاز آن منطقه تهیه میکرد کاملاً با رایانهای که در نقطهای دیگر این کار را انجام میداد متفاوت بود(تصور کنید در چنین سیستمی یک ایمیل از یکی از این دو رایانه به دیگری ارسال شود و در محتوای آن از نویسههای موجود در 128 آدرس دوم مبدأ استفاده شود، در این صورت نویسههای موجود در متون نوشتههای اولی به صورت ترکیبی نامفهوم از نویسههای موجود در کدگذاری مقصد ترجمه شده و به نمایش در میآید! البته در آن زمان هنوز ایمیل اختراع نشده بود!)
با توجه به اختلاف شرکتهای رایانهای محلی در کدگذاری، لازم بود توافقی بین آنها در مورد یک کدگذاری قابل استفاده در یک منطقه بوجود آید تا بتوان از یک فایل در تمام رایانههای یک کشور استفاده کرد. به همین دلیل کدگذاریهای استانداردی بوجود آمدند که 128 آدرس دوم را بنا به زبانهای مورد استفاده در مناطق جغرافیایی مختلف درون مرزهای یا چند کشور دستهبندی میکردند. برای مثال code page 1256 شامل نویسههای عربی پایه به علاوۀ نویسههای موردنیاز برای پشتیبانی از زبان فارسی در ایران است.(code page جدولیست که نویسههای مختلف را با کدهای هگزادسیمال مرتبط میکند، از این اصطلاح تنها برای کدگذاریهای محلی استفاده میشود)
اگر چه این کدگذاریها در اغلب موارد کافی بودند اما نمیشد نوشتارها و زبانهای شرق آسیا(مخصوصاً زبانها و خطوط نوشتاری CJK، یعنی چینی، کرهای و ژاپنی) را فقط با 128 آدرس دوم پوشش داد. برای پوشش این خطوط نوشتاری و زبانهای مرتبط با آنها از کدگذاریهای ابداعی DBCS استفاده شد. DBCS مخفف Double-Byte Character Set کدگذاریهای 2 بایتی هستند که در مجموع 65536 نویسه را میشود با آنها پوشش داد.
مریت اصلی کدگذاریهای محلی فشرده و کم حجم بودن نویسهها و ضعف اصلی آنها نحوۀ پشتیبانی در سیستمهای مقصد است، به این معنی که باید تمام code page های موجود در جهان در یک سیستم رایانهای وجود داشته باشد تا بتوان از تمام محتوای نوشته شده در جهان پشتیبانی کرد!
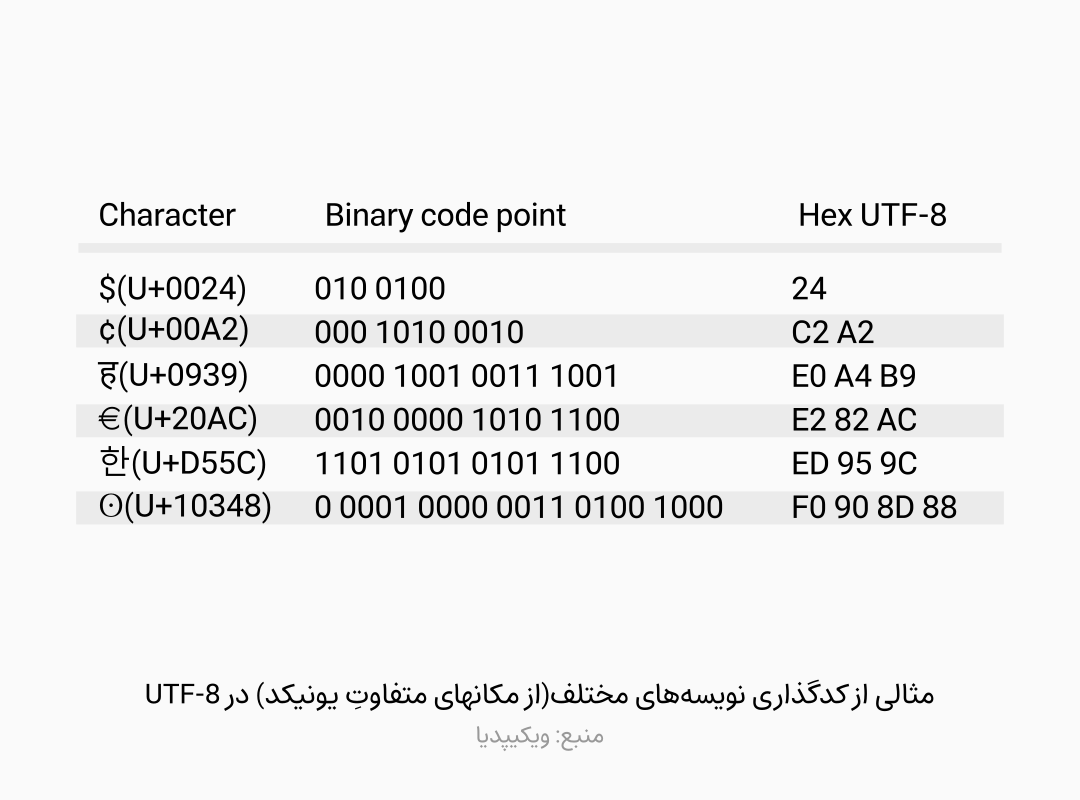
در اینجا لازم است به تفاوت مفهوم کدگذاری(encoding) و مجموعهنویسه(character set) توجه شود. در مجموعهنویسه، مجموعهای از حروف، اعداد و علائم وجود دارند که به هر یک از آنها عددی منحصر بفرد اختصاص یافته است؛ در حالیکه در تعریف کدگذاریْ قالبی برای ذخیره و انتقال این نویسهها نیز معرفی میشود، خودِ این قالب میتواند بلوکهای ساده(مانند بلوکهای 7 یا 8 بیتی استفاده شده در کدگذاری ASCII) یا همانگونه که در ادامه تشریح خواهد شد بلوکهای پیچیدهتر با طول متغیر(مانند بلوکهای 1 یا 2 یا 3 یا 4 بایتی در کدگذاری UTF-8) باشد.
یونیکد و کدگذاریهای سری UTF
با افزایش ارتباطات و مخصوصاً ایجاد و توسعۀ اینترنت و با توجه به ضعف کدگذاریهای محلی نیاز به یک code page مستقل از کدگذاری که تمام حروف و علائمِ خطوط نوشتاری و زبانهای زندۀ دنیا را پوشش دهد بسیار ضروری بود، به همین خاطر یونیکد بوجود آمد تا همۀ نویسههای نوشتاری و کنترلی موجود در جهان را به ترتیب در یک آدرسدهی غیرقابل تغییر گرد هم آورد و کدگذاریهای جدیدتر جهانی از ترتیب موجود در آن تبعیت کنند. با این کار تمام دنیا روی یک مجموعهنویسۀ جهانی توافق کردند و نمایندگانی از تمام کشورها برای توسعۀ آن گرد هم آمدند. این کار عظیم همچنان ادامه دارد. به این code page بسیار بزرگ، یونیکد میگویند.
یونیکد همواره از تمام نسخههای قبلی خود پشتیبانی میکند(اصطلاحاً دارای backward compatibility است) با این کار مشکلی برای متون تایپ شدۀ دیجیتالی قدیمی و رایانههای قدیمی بوجود نخواهد آمد.
کدگذاریهای سری UTF از code page یونیکد تبعیت میکنند، UTF-8 کدگذاری 8 تا 32 بیتی(8 یا 16 یا 24 یا 32 بیت)، UTF-16 کدگذاری 16 تا 32 بیتی(16 یا 32 بیت) و UTF-32 یک کدگذاری 32 بیتیست.
کدگذاری با عرض بیت ثابت و متغیر
قبلاً اشاره کردیم که تعداد نویسههای دستهبندی شده در یک کدگذاری میتواند سرعت خواندن، نوشتن، انتقال و حجم ذخیرهسازی دادهها را تعیین کند. و از این جهت کدگذاریهایی با عرض بیت کمتر مزیت دارند، اما ترجیح کلی به سمت استفاده از کدگذاریهای جهانیست که تعداد نویسههای بسیار بیشتری را پشتیبانی میکنند(زیرا تعداد سیستمهایی که ازخطوط نوشتاری مختلف استفاده یا از آنها پشتیبانی میکنند رو به افزایش است، ضمن آنکه پشتیبانی از چند کدگذاری جهانی به مراتب راحتتر و کم دردسرتر از پشتیبانی از همه یا تعدادی از کدگذاریهای محلیست زیرا نیازی به تبدیل یا پشتیبانی از تمام آنها در سیستمهای مختلف نیست…) پس راهحل چیست؟ استفاده از کدگذاریهایی با عرض بیت متغیر! در این کدگذاریها عرض بیتْ نسبت به نویسۀ مورد استفاده تغییر میکند! نحوۀ رمزگشایی این کدگذاریها کمی دشوارتر است. به عنوان مقایسه، کدگذاریهای سری UCS(مانند UCS-2 و UCS-4) دارای عرض بیت ثابت و کدگذاریهای سری UTF(مانند UTF-8 و UFT-16 و UTF-32) دارای عرض بیت متغیر هستند.
مقایسۀ UCS و UTF-8
در اینجا 2 نمونه از کدگذاریهای عرض بیت ثابت و متغیر، یعنی UCS و UTF-8 را تشریح میکنیم. USC یک کدگذاری منسوخ شده با عرضِ بیتِ ثابتِ 8 بیتی و UTF-8 پیچیدهترین کدگذاری عرضِ بیتِ متغیر با حداقل عرضِ 8 بیت است.(چون حداقلْ دادههای مورد بررسی در این تحلیل 8 بیت دارند که برابر یک بایت میشود، در ادامه از واژۀ بایت استفاده میکنیم) در محدودههای مشخصی که هر دو کدگذاری از یک بایت برای کدگذاری نویسهها استفاده میکنند(بیشتر در گسترۀ ابتدایی یونیکد) نتیجه یکسان است، اما در محدودههای خاصی UTF-8 بر خلاف USC که از همۀ ظرفیت خود برای کدگذاری استفاده میکند، از بایت اول برای گسترش محدودۀ خود استفاده میکند، بدین معنا که در این محدود، بایت اول به تنهایی اطلاعاتی دربارۀ کدگذاری نویسه نمیدهد، بلکه تعیین آن نویسهها را منوط به بررسی بایتهای بعدی میکند، با این کار تعداد حالات به اندازۀ محدودهای که بایت دوم میتواند در آن تغییر کند افزایش مییابد، اما از بخشی از حالات خود بایت دوم نیز برای افزایش محدوده استفاده میشود و …و همینطور از بایت سوم! این افزایش محدوده تا حداکثر چهار بایت ادامه مییابد.(در جداولی که در تصویر قبل و بعد ارائه شده این روند کاملاً مشهود است)
حال 2 سوال پیش میآید:
1-چرا عرض بلوکها ثابت است و صفرهای سمت چپ حذف نمیشوند تا حجم کدگذاری کاهش یابد؟
– زیرا غیر از عرض ثابت این بلوکهای اطلاعات، ملاک دیگری برای تشخیص شروع و پایان کدگذاری یک نویسه وجود ندارد!
2- چرا با اینکه UTF-8 تا این حد بهینه است، UTF-16 و UTF-32 ساخته شدهاند؟
– زیرا کدگذاری UTF-8 برای نویسههای موجود در ابتدای یونیکد بهینه شده است اما هر چه به خانههای آخر نزدیک میشویم نسبت به UTF-16 و UTF-32 تعداد بایتهای بیشتری برای کدگذاری نویسهها نیاز دارد. در تصویر زیر دیده میشود که نویسۀ A دارای 1 بایت(=8 بیت= یک جفت رقم هگزادسیمال یا 8 رقم دودویی) در UTF-8 و، 2 بایت در UTF-16 و 4 بایت در UTF-32 است، اما نویسۀ «ﺖ» دارای 3 بایت در UTF-8 و، 2 بایت در UTF-16 و 4 بایت در UTF-32 است، همچنین ایموجی 😀 با آنکه در هر 3 کدگذاری 4 بایت دارد اما دیده میشود که در انتهای ظرفیت چهاربایتی UTF-8، تقریباً در 85 درصدِ انتهاییِ UTF-16 و به صورت ناباورانهای در 1 درصد ابتدایی UTF-32 قرار گرفته است! بنابراین با ادامۀ این روند کاملاً واضح است که در آدرسهای بالاتر UTF-32 حجمی کمتر از UTF-16 و آن هم حجمی کمتر از UTF-8 برای کدگذاری نویسهها مصرف خواهد کرد. از طرف دیگر استفاده از UTF-16 و UTF-32 در یک محدودۀ گسترده که عرض کدگذاری نویسهها در آن ثابت است مزیتِ استفاده از یک کدگذاری با عرض بیت ثابت را فراهم میکند.

مفاهیم BOM و LE/BE در سری UTF
برای معرفی نحوۀ کدگذاری در فایل از روشی که برای امضای دیجیتالی در ابتدای فایلها وجود دارد استفاده میشود(file signatures)، در مورد کدگذاری به این امضا Byte order mark یا به اختصار BOM گفته میشود. وجود داشتن BOM در یک فایل اختیاریست، ممکن است خود سیستم از کدگذاری پیشفرضی برای رمزگشایی فایل استفاده کند، UTF-8 یکی از این پیشفرضهاست بنابراین کدگذاریهای UTF-8 ممکن است فاقد BOM باشند.
ترتیب چیدن بایتهای یک نویسه در فایلهای دیجیتالی ممکن است از کمارزش به باارزشتر(Big Endian=BE) و بالعکس باشد(Little Endian=LE). (نامگذاری LE/BE برای ترتیب چینش، از داستان سفرهای گالیور برداشته شده است) به طور مثال نویسۀ 😀 در UTF-32BE برابر است با 0001F603و در UTF-32LE میشود 03F60100
(هر جفت عدد هگزادسیمال برابر با یک بایت است)
کدگذاری GSM-7 و UTF-16 در پیامکها(SMS)
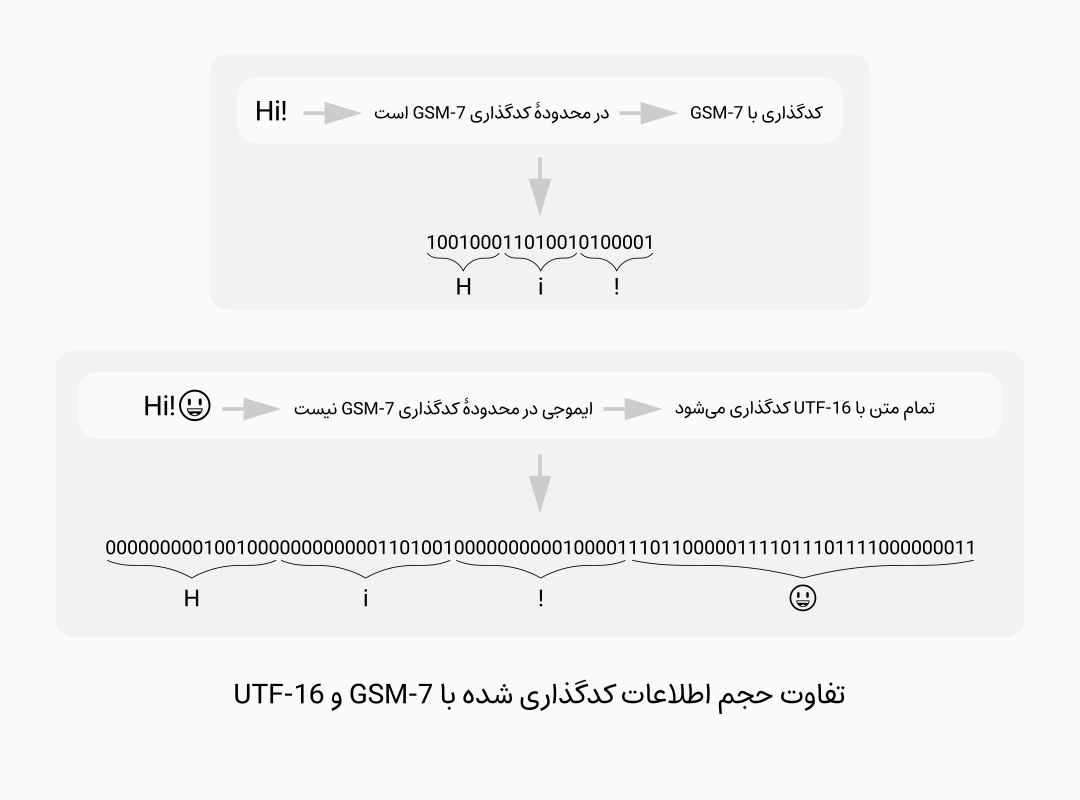
هر عدد پیامکی که در گوشیهای همراه ارسال و دریافت میشود حداکثر میتواند حاوی 140 بایت دادۀ متنی باشد(منظور از دادۀ متنی، حجم خالص دادهها غیر از متادیتاهاییست که شیوۀ کدگذاری و اطلاعات دیگر را به همراه دارند)، در این پیامکها برای لاتین پایه و کاراکترهای پرکاربردی که در ابتدای یونیکد قرار گرفتهاند از کدگذاری 7 بیتی GSM-7 و تا همین اواخر برای نویسههای موجود در لاتین الحاقی، خطوط نوشتاری دیگر از جمله عربی و زبان فارسی و … از کدگذاری 16 بیتی عرض ثابت UCS-2 استفاده میشد اما با گسترش یونیکد اکنون از کدگذاری عرض بیت متغیر UTF-16(با عرض بیت 16 یا 32 بیتی) به جای UCS-2 استفاده میشود. در کدگذاری GSM-7 تعداد حداکثرِ تعداد نویسهها برابر است با:140×8÷7=160و در کدگذاری UTF-16 با فرض تمام نویسهها در محدودۀ 16 بیتی، حداکثر برابر است با:140×16÷7=70 و با فرض حضور تمام نویسهها در محدودۀ 32 بیتی، حداقل برابر است با: 140×32÷7=35
معمولاً خود گوشیهای هوشمند با توجه به ورودی متنْ کدگذاری متناسب با آن را انتخاب میکنند، بنابراین با اضافه کردن یک ایموجی (ایموجی مثالی از یک نویسۀ خارج از محدودۀ GSM-7 است، بدیهیست که بسیاری از حروف و علائم خارج از این محدوده هستند، از جمله حروف و علائم نوشتار عربی و فارسی و …) به نویسههای نوشته شده و موجود در محدودۀ کدگذاری GSM-7 حجم پیامک به صورت قابل ملاحظهای افزایش مییابد!(میتوانید 159 نویسۀ انگلیسی داخل پیامک تایپ کنید و با اضافه کردن یک ایموجی تغییر حجم لازم از 1 پیامک به 3 پیامک را مشاهده کنید.)
مثالی از متن دیجیتال با کدگذاریهای سری UTF
در اینجا یک متن نمونه یکسان و کوچک را در هر سه کدگذاری UTF-8، UTF-16 و UTF-32 تحلیل میکنیم. متن نمونه حاوی نویسههای لاتین(لاتین پایه: حروف انگلیسی و اعداد لاتین)، عربی(حروف و اعداد فارسی) و ایموجیست:
متن نمونه:
Hello Guys 👀
سلام بچهها 👋
تحلیل با کدگذاری UTF-8:

تحلیل با کدگذاری UTF-16BE:

تحلیل با کدگذاری UTF-32BE:

منابع
– ویکیپدیا
– اطلاعات شخصی برگرفته از مقالات پراکنده در اینترنت
-مجموعهای از گفتگوهای کوتاه با آقای روزبه پورنادر (این گفتگوها باعث درک بسیار بهتر و عمیقتری شد، همینجا از زحمات ایشان سپاسگزاری میکنم.)


خوب بود و تخصصی. چیزی یاد گرفتیم.
مگه طراحی فونت هم برنامه نویسی میخواد؟!!!!🤯🤯🤯
به خاطر علاقه دوست داشتم رشته گرافیک برم ولی برنامه نویسی اصلا بلدم نیست
یعنی دیزاینر تایپ بدون برنامه نویسی نمیتونه فونت بسازه و همه فونت های موجود برنامه نویسی شده؟
همه طراحایی که میخوان فونت طراحی کنن باید برن برنامه نویسی یاد بگیرن مثل شما یعنی هم رشته گرافیک برن هم برنامه نویسی یاد بگیرن راه بدون برنامه نویسی وجود نداره؟
اصلا براچی نیاز به برنامه نویسیه ایا به خاطر وریبل کردن و اجرا تویه وبه؟
میشه بگید با چه زبان هایی برنامه نویسی فونت میکنن؟
برنامه نویسی بیشتر برای قسمت ساخت یا مهندسی فونت لازمه. کارهای تکراری ساده و زیاد رو میشه سپرد به رایانه. برای این کار استفاده از api پایتون خود برنامۀ ساخت فونت روش راحت و مرسومی هست.
چی میتونم بگم جز “برگام” خیلی تخصصی بود واقعا تشکر که وقت گذاشتید برای این مقاله
ممنونم از لطف شما 🙂